AI-OCRもLLMも万能じゃない ― “Excel地獄”が残る理由
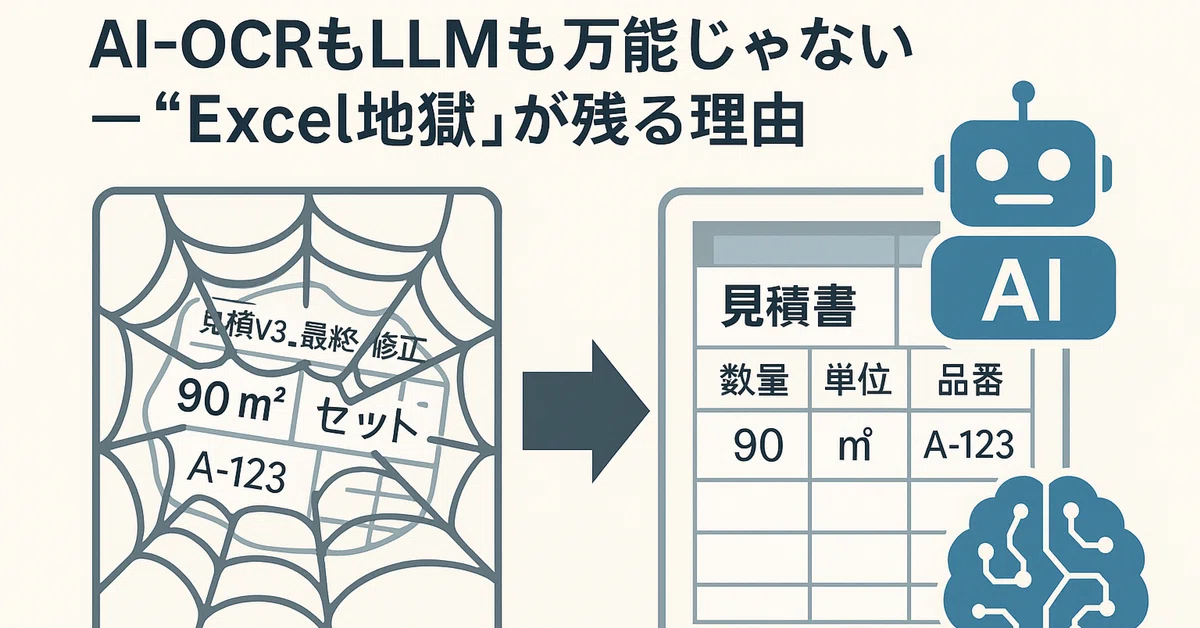
AI-OCRやLLMを入れたのに、最後はExcelで人が整えている──。
建設・製造・流通の現場で何度も見てきた“あるある”です。
原因は「AIの精度」よりも、現場の情報構造にあります。
1. よくある誤解と現実
誤解1: AI-OCRが正確に読めれば手作業は消える
現実: 読めてもどのマスタと結びつけるか(型番⇔メーカー、仕入先⇔正式名)で詰まる
誤解2: LLMに投げれば自動で整う
現実: LLMが推測した“それっぽい答え”は業務ルールの保証がない(監査・原価に不安)
誤解3: Excelは柔軟で便利だから残しておけばOK
現実: Excelは入力・命名・計算式が自由すぎて“例外スノーボール”を起こす
2. “Excel地獄”の典型症状(建設の見積・契約・予算)
- 非正規化の列
- 「摘要」に仕様・例外・社内メモが全部入り
- 行結合/セル結合で機械可読性ゼロ
- 名寄せできないマスタ
- 「〇〇電設」「(有)〇〇電設」「〇〇電設(株)」が別会社扱い
- 型番「A-123」「A123」「A‐123(全角ハイフン)」の表記ゆれ地獄
- 単位・数量のブレ
- m / m(全角)/ m² / セット / 本 の混在
- 端数処理や歩掛の社内ルールが暗黙知
- 版管理の迷子
- 「見積v3_最終_藤井修正_確定(案).xlsx」…どれが最新?
- 誰が、いつ、何を直したか監査不能
結果、AIが「読めた」あとに“人の判断”を呼び戻す構造が残る。
これがExcel地獄の正体です。
3. 技術的にどこで詰まるのか(分解して見る)
- 文字認識(OCR):活字は高精度でも、スキャン品質/罫線つぶれ/押印/手書きで劣化
- 構造復元:表の見出し・階層・小計の意味づけはルール化が必要
- 正規化:全半角、ハイフン、スペース、単位、桁区切りを統一
- エンティティ解決(名寄せ):仕入先名・型番・工種名を社内マスタに紐付け
- 業務ルール適用:歩掛、社内原価、相当品可否、閾値アラートなど会社ごとの判断
- 例外学習:人が直した痕跡を再利用できる仕組みがないと、毎回“初見作業”に逆戻り
精度95%でも、1日100行なら5行は例外。
その5行が各社固有ルールに絡むと毎回、人の登板になります。
4. 解決アーキテクチャ:6層モデル
- Ingestion(取り込み)
スキャン/PDF/メール添付/クラウド(SharePoint/Box…)を一元取込。命名規則とメタデータ付与。 - Parse(OCR/レイアウト解析)
ページ単位→表構造→見出し/小計/脚注を抽出。セル結合の解除と階層の平坦化。 - Normalize(正規化)
表記ゆれ・単位換算・全半角・ハイフン・数値書式を関数/辞書で機械的にまず揃える。 - Resolve(名寄せ)
仕入先名・メーカー・型番・工種を確率スコア付きで候補提示(fuzzy join)。
人が選んだ結果を同義語辞書に継ぎ足す。 - Rules(業務ルール)
歩掛、閾値、原価・相当品可否、承認経路を宣言的ルール(YAML/DSL)で管理。
LLMは“提案”止まり、確定はルールが決める。 - HITL & Feedback(人の判断ログ化)
人の修正を原子操作として記録(誰が・何に対し・どう直したか)。
辞書/ルール/名寄せモデルへ自動還元して“二度目は起きない”を担保。
ポイントは、「人の判断」を一次データとして永続化すること。
YOZBOSHIでは14万件規模の判断ログを学習に回し、例外の再発率を継続的に下げます。
5. Excelの“正しい残し方”
- DBが真実、Excelはビュー:真実は構造化DB/JSON。Excelは出力と承認のUIに限定
- 入力はフォーム化:Excel直接入力をやめ、検証付きフォームで収集
- 差分トラッキング:Excel 書き戻しはやめ、差分比較画面でレビュー・承認
- 監査ログ:版管理をIDと履歴で。ファイル名運用は卒業
6. 60日導入ロードマップ(現実解)
Week 1–2|可視化
- 代表的なExcel/見積PDFを収集、列定義・小計・脚注・例外を棚卸し
- “例外の目録”を作る(名寄せ失敗例、単位ゆれ、承認戻り理由)
Week 3–4|辞書と正規化
- 仕入先名・メーカー・型番の同義語辞書を初期投入
- 単位変換と書式正規化ルールをコード化
Week 5–6|名寄せ+ルール
- fuzzy join(候補3件+スコア)→人が1クリックで確定
- 歩掛・原価・アラートのYAMLルールを実装、承認フロー接続
Week 7–8|HITL学習と運用化
- 修正ログ→辞書/ルールへ自動反映のパイプライン
- KPIダッシュボード:例外率、再発率、辞書ヒット率、承認リードタイム
7. KPI設計(ビフォー/アフターが見える化)
- 例外率(人手が必要な行の割合)
- 再発率(同タイプ例外の再出現/月)
- 辞書ヒット率(名寄せが自動確定した比率)
- 承認リードタイム(提出→確定までの時間)
- Excel開封回数/件(“脱Excel”の体感指標)
まずは例外率▲30%・再発率▲50%を初期目標に。
“ゼロ例外”ではなく、“同じ例外を二度と起こさない”が現実的で強い。
8. 現場でそのまま使えるチェックリスト
- 「摘要」に埋もれている業務判断を列に分離したか
- 単位辞書(m/㎡/本/セット…)と換算ルールを定義したか
- 同義語辞書に社内ニックネーム(略称)を含めたか
- 名寄せ候補はスコアと根拠を併記しているか
- 人の修正が自動で辞書/ルールに戻る仕組みになっているか
- Excelは出力/承認ビューとして限定されているか
9. まとめ
AI-OCRもLLMも強力です。ただし“人の判断をどう再現し続けるか”を設計しない限り、Excel地獄は形を変えて残ります。
解は、正規化→名寄せ→ルール→判断ログの循環をつくること。
“例外が学習資産になる現場”へ、今日から移行しましょう。
Connected Baseのご紹介
「AI-OCR」「RPA」から
“LLM+人の判断”の再現へと移りつつあります。
Connected Base は、日々の見積書・請求書・報告書など、
人の判断を必要とする“あいまいな領域”を自動で処理し、
現場ごとのルールや判断のクセを学習していくAIプラットフォームです。
これまで人が時間をかけて行ってきた仕分けや確認を、
AIとルール設定だけで再現・蓄積・自動化。
単なる効率化ではなく、「判断の継承」まで含めたDXを実現します。
現場の知恵を未来につなぐ──
その第一歩を、Connected Baseとともに。



コメントを送信